Common LispでLALR(1)のparserを作る3
前回:Common LispでLALR(1)のparserを作る2 - nptclのブログ
1. 続きです
Common LispでひたすらLR(1)を作成するコーナーです。
CLOSUREまで作ったので、状態遷移表の作成に入ります。
2. GOTO
CLOSUREができたら、次はGOTOを作りましょう。
まずは定義から。
;; GOTO(I, X) ;; J = (); ;; foreach ([A -> alpha . X beta, a] in I) ;; add [A -> alpha X . beta, a] to J; ;; return CLOSURE(J);
GOTOは、集合Iから記号Xで遷移した新たな集合を取得します。
Xは、終端記号でも非終端記号でもどちらでもかまいません。
定義を見てもらえば分かる通り、
[A -> alpha . X beta, a] が [A -> alpha X . beta, a]
になっています。
ドットを前進させた集合を作り、
それをCLOSUREに渡したものが返却値です。
コードは難しくはありません。
(defun goto-parse (list x) (let (root) (dolist (g list) (awhen (goto-next g x) (push it root))) (closure-parse root)))
GOTO(I, X)が、(goto-parse list x)になります。
listをひとつずつ見ていき、goto-nextが返却した場合にpushします。
最終的に得られた集合をclosure-parseに渡して終了です。
(defun goto-next (g x) (awhen (grammar-beta g) (destructuring-bind (y . beta) it (when (eql x y) (let ((left (grammar-left g)) (alpha (grammar-alpha g)) (ahead (grammar-ahead g))) (setq alpha (append alpha (list y))) (grammar-instance left alpha beta ahead))))))
goto-nextは、grammar-betaが(x . beta)の形になっているものを探します。
見つかったらドットを前進させ、新しいinstanceを作って返却です。
4. 集合の確認
ここからは、集合Iの内容に応じた状態遷移表を作っていきます。
まず考えなければいけないのは、集合が等しいという判定です。
集合とは、順不同のリストだと思ってください。
例えば、次の二つの集合は等しいです。
(a b c) (c a b)
集合が等しいかどうかの判定を行う関数equalsetを作ります。
(defun equalset-find (x right test) (dolist (y right) (when (funcall test x y) (return t)))) (defun equalset-call (left right test) (dolist (x left t) (unless (equalset-find x right test) (return nil)))) (defun equalset (left right &key (test #'eql)) (and (listp left) (listp right) (= (length left) (length right)) (equalset-call left right test)))
何をしているのかというと、下記の実行が行われた場合、
(equalset left right)
まずleftとrightの長さが等しいかどうかを見ます。
そのあとにleftの要素一つずつ取り出して、
全部rightに含まれるかどうかを確認します。
5. 状態の作成
次に状態を作っていきましょう。
状態は、整数の番号であらわされるものとします。
集合Iの内容に応じて状態が作成されます。
まずは構造体と変数から見ていきます。
(defstruct state index list action goto) (defvar *state-index* 0) (defvar *state* nil)
state構造体は、通し番号indexと集合listを持ちます。
actionとgotoは、状態遷移の矢印を意味します。
actionにはshiftとreduceの動作が入り、
gotoにはreduce後の遷移先が入ります。
変数である*state-index*は、indexの通し番号に使います。
*state*は、状態を格納するリストです。
状態の番号から、state構造体を取得する関数を作成します。
(defun get-state (index &optional (errorp t)) (or (find index *state* :key #'state-index) (when errorp (error "Index error, ~S." index))))
get-stateは、単にfindしてるだけなので簡単です。
次に、集合listから状態を取得する関数を示します。
(defun intern-make-state (list) (aprog1 (make-state :index *state-index* :list list) (push it *state*) (incf *state-index*))) (defun intern-state (list) (or (intern-find-state list) (values (intern-make-state list) t)))
intern-stateは、まずintern-find-stateで検索を行います。
既に存在しているならその構造体を返却します。
存在しないならintern-make-stateで構造体を作成して返却します。
もし構造体が作成された場合は、(values instance t)のように、
第二返却値がtになります。
次にintern-find-stateを見てみます。
(defun intern-find-state (list) (dolist (y *state*) (when (equalset list (state-list y) :test #'grammar-equal) (return y))))
この関数は、リスト*state*から集合listに対応する構造体をfindしています。
keyが集合listで、valueが状態というhash-tableの索引みたいなものです。
注意点としては、集合listは順不同なのでequalsetを使う必要があるということ。
equalsetの:testには、grammar-equalが指定されています。
(defun grammar-equal (x y) (and (equal (grammar-left x) (grammar-left y)) (equal (grammar-alpha x) (grammar-alpha y)) (equal (grammar-beta x) (grammar-beta y)) (equalset (grammar-ahead x) (grammar-ahead y))))
grammar-equal関数は、引数xとyが等しいかどうかを調べます。
left, alpha, betaは普通にequalで確認しますが、
aheadだけは集合なので、equalsetを用いています。
6. 状態遷移表の作成
それでは開始記号をもとに、状態遷移表を作成します。
まずは開始記号から初期状態を作りましょう。
(defun start-table () (let* ((left *start-symbol*) (beta (list *start*)) (ahead *end*) (x (grammar-instance-rest left nil beta ahead))) (intern-state (closure-parse (list x)))))
初期状態の集合については前回解説しました。
もう一度書くと、
#:start -> . expr, #:end
というたったひとつの集合をCLOSUREに渡しています。
前回と違うのは、CLOSUREの返却値をintern-stateに渡して状態を作成している所です。
start-tableは、開始記号の集合に対応する初期状態が返却されます。
ついでに、一度実行したら全部同じ状態が返却されるのを確認してみましょう。
(format t "~S~%" (start-table)) (format t "~S~%" (start-table)) (format t "~S~%" (start-table))
実行結果は下記の通り。
#S(STATE :INDEX 0 ...) #S(STATE :INDEX 0 ...) #S(STATE :INDEX 0 ...)
indexがインクリメントされずに全部0になっているのが分かります。
それではGOTOを使って次々に遷移していきましょう。
まずは開始の関数を制定します。
(defun make-table () (make-table-loop (start-table)))
make-tableは、初期状態を作成してから
すぐmake-table-loopを呼んでるだけです。
(defun make-table-loop (x) (dolist (s (symbols-table x)) (multiple-value-bind (y make) (goto-table x s) (arrow-table s x y) (when make (make-table-loop y)))))
make-table-loopは短いにしては色々やっています。
まず状態xから遷移できる記号を全部集めます。
終端記号・非終端記号どちらも全部取得します。
次に状態xと記号sを引数に、GOTOで遷移させて状態yを取得します。
遷移元xと遷移先yを、記号sと一緒に状態遷移表に追加します。
もし遷移先yが新しく作成されたものであったなら、
make-table-loopを再帰呼出します。
関数がいくつかあります。
symbols-table
状態から遷移する記号をリストで全部取得するgoto-table
GOTOを実行して状態を取得するarrow-table
元の状態と新たな状態を、記号で遷移させる
順番に見ていきましょう。
(defun symbols-table (x) (let (root) (dolist (g (state-list x)) (awhen (grammar-beta g) (pushnew (car it) root))) root))
symbols-tableは、状態xが保有する集合を全部見て、遷移先の記号をすべて取得します。
どういうことかというと、集合の中のbetaのcarを集めます。
文法っぽく書くならば、
[left -> alpha . X beta, ahead] in I
のXを集めます。
(defun goto-table (x s) (intern-state (goto-parse (state-list x) s)))
goto-tableは簡単ですね。
状態が保有する集合をGOTOに渡して、intern-stateで状態を取得しています。
goto-tableの返却値は、intern-stateの第二返却値も必要なことに注意してください。
状態は必ず作成されるのではなく、
すでに同じ集合があるならそれが返却されます。
(defun arrow-table (s x y) (let ((next (state-index y))) (cond ((terminalp s) (add-shift-table s x next)) ((non-terminal-p s) (add-goto-table s x next)) (t (error "Invalid symbol, ~S." s)))))
arrow-tableは状態xに遷移先を登録します。
これは少し説明が必要です。
状態xから記号sで遷移するとき、
記号sが終端記号か非終端記号かのどちらかで動作が変わります。
終端記号の場合は、状態のactionにshiftとして登録します。
非終端記号の場合は、状態のgotoに遷移先を登録します。
reduceはどうしたんだという話ですが、まだ出てきません。
ということで、arrow-tableは呼び出す関数を変えているのです。
(defun state-action-check-p (y z b c) (and (eq b y) (or (eql c z) (and (rule-p c) (rule-p z) (eql (rule-index c) (rule-index z)))))) (defun state-action-check (list a b c) (destructuring-bind (y z) (cdr list) (unless (state-action-check-p y z b c) (error "~S/~S error, ~S, ~S." y b list (list a b c))))) (defun add-shift-table (s x next) (aif (find s (state-action x) :key #'car) (state-action-check it s 's next) (push (list s 's next) (state-action x))))
add-shift-tableは終端記号を登録するための関数です。
まずはactionテーブルに同じ記号が登録されているかどうかを確認します。
登録されていた場合、state-action-checkで確認を行います。
もし全く同じものが登録されていた場合は問題ありません(state-action-check-pで確認)。
しかし違うのならエラーの可能性があります。
今の段階では、無条件にエラーにしてしまっています。
後で話題に出すかもしれませんが、Shift/Reduce衝突と呼ばれるものは
無視したりする場合もあります。
そういう時はstate-action-checkをいろいろいじって下さい。
もし登録されていないのであれば、状態のactionにShift操作として登録します。
pushする内容が
(list s 's next)
となっていますが、二番目の'sがShiftを意味しています。
他にも'rがReduce、'aがAcceptになります。
それでは非終端記号の方を示します。
(defun state-goto-check (list a b) (destructuring-bind (y) (cdr list) (unless (eql b y) (error "goto error, ~S /= ~S." list (list a b))))) (defun add-goto-table (s x next) (aif (find s (state-goto x) :key #'car) (state-goto-check it s next) (push (list s next) (state-goto x))))
こちらはShiftやReduceなど種類がありません。
たんに記号と遷移先の2つの情報をpushしています。
もちろん衝突チェックは入れています。
7. 状態遷移表の確認
ここまででshiftの遷移表までは完成しました。
Reduceをやる前にちょっと動作確認をしてみましょう。
状態の確認に使う出力関数です。
(defun output-action-table (x) (destructuring-bind (a b c) x (if (rule-p c) (format nil "~A:~A:~A" a b (rule-index c)) (format nil "~A:~A:~A" a b c)))) (defun output-goto-table (x) (destructuring-bind (a b) x (format nil "~A:~A" a b))) (defun output-table () (dotimes (index *state-index*) (awhen (get-state index nil) (let ((a (mapcar #'output-action-table (state-action it))) (g (mapcar #'output-goto-table (state-goto it)))) (format t "~3A:~{ ~A~}~40T~{ ~A~}~%" index a g)))))
それではoutput-tableを実行してみます。
0 : INT:S:19 [:S:6 FACT:20 TERM:21 EXPR:1 1 : +:S:2 2 : INT:S:19 [:S:6 FACT:20 TERM:3 3 : *:S:4 4 : INT:S:19 [:S:6 FACT:5 5 : 6 : INT:S:17 [:S:12 FACT:16 TERM:15 EXPR:7 7 : ]:S:18 +:S:8 8 : INT:S:17 [:S:12 FACT:16 TERM:9 9 : *:S:10 10 : INT:S:17 [:S:12 FACT:11 11 : 12 : INT:S:17 [:S:12 FACT:16 TERM:15 EXPR:13 13 : ]:S:14 +:S:8 14 : 15 : *:S:10 16 : 17 : 18 : 19 : 20 : 21 : *:S:4
大きく左の列がactionで、右の列がgotoです。
状態0のactionにあるINT:S:19というのは、
終端記号がint,種類がshift,遷移先が19という意味です。
gotoは非終端記号に対して、遷移先の番号が対応しているのが分かります。
例えばFACT:20というのは、非終端記号FACT, 遷移先20という意味です。
goto表がいったい何者なのかは、実際に動かしてみるときに説明します。
8. Reduce表の作成
続けてReduceの遷移を作成します。
Shiftはもう作成してあるので、Reduceが終わればLR(1)が完成ということになります。
Reduceの遷移は、全ての状態を個別に見ていく必要があります。
さらに状態の中の集合を一つずつ見ていきます。
集合内の要素と全ての規則を比べて、どれかに一致しているかを見ていきます。
とにかく地道に一つずつ見ていきます。
何をどう見ていくかというと、
[expr -> expr + term . A B C, +/int]
みたいな文を含む集合を持った状態があったとします。
この文は、次の規則を適用できます。
(parse-rule expr -> expr + term)
つまり、文のleftとalphaを見て、
それが規則のleftとrightと一致するものを探すのです。
もし一致するのであれば、その規則でReduceする遷移をactionに追加します。
遷移記号は終端記号であり、その文が保有するaheadになります。
つまり今回の場合は+とintです。
遷移先は登録しませんが、後でgotoをもとに遷移する方法を説明します。
それではやっていきましょう。
(defun make-reduce () (dolist (x *state*) (dolist (g (state-list x)) (awhen (find-reduce g) (add-reduce x g it)))))
この関数は2つのdolistがあります。
最初のdolistは全ての状態に対して行います。
次のdolistは、状態の全ての集合に対して行います。
もしfind-reduceでReduceする規則が見つかったら、add-reduceでactionに追加します。
(defun find-reduce (g) (let ((left (grammar-left g)) (alpha (grammar-alpha g))) (dolist (rule *rule*) (and (equal (rule-left rule) left) (equal (rule-right rule) alpha) (return rule)))))
dolistを用いて、全ての*rule*にfindをしています。
条件は、文のleftとalphaがそれぞれ規則のleftとrightに等しいことです。
(defun add-reduce (x g rule) (dolist (s (grammar-ahead g)) (if (rule-accept rule) (add-final-table s x) (add-reduce-table s x rule))))
もしReduceできる規則があった場合は、
add-reduceでaheadの分だけactionに追加されます。
ただし、見つかった規則がacceptかどうかで分岐します。
acceptとは、開始記号かどうかです。
もし開始記号の場合は、構文解析が「受理」しますので、また別の処理となります。
まずは普通のreduceの場合を見ていきます。
(defun add-reduce-table (s x rule) (aif (find s (state-action x) :key #'car) (state-action-check it s 'r rule) (push (list s 'r rule) (state-action x))))
追加はshiftのときのadd-shift-tableと同じです。
追加する記号が既に存在する場合は、
内容が全く同じなら問題ありませんが、違う場合は衝突です。
存在しない場合は、(list s 'r rule)を追加します。
Shiftの場合とは違い、'rとruleそのものが格納されます。
遷移先の番号ではないので注意。
続いてaccpetの場合です。
(defun add-final-table (s x) (aif (find s (state-action x) :key #'car) (state-action-check it s 'a nil) (push (list s 'a nil) (state-action x))))
追加する内容は、(list s 'a nil)です。
以上で、LR(1)の遷移表はすべて完成です。
実際に実行してみましょう。
(parse-terminal + * [ ] int) (parse-start expr) (parse-rule expr -> expr + term) (parse-rule expr -> term) (parse-rule term -> term * fact) (parse-rule term -> fact) (parse-rule fact -> [ expr ]) (parse-rule fact -> int) (make-table) (make-reduce) (output-table)
実行結果は下記の通り。
0 : INT:S:19 [:S:6 FACT:20 TERM:21 EXPR:1 1 : END:A:NIL +:S:2 2 : INT:S:19 [:S:6 FACT:20 TERM:3 3 : END:R:1 +:R:1 *:S:4 4 : INT:S:19 [:S:6 FACT:5 5 : END:R:3 +:R:3 *:R:3 6 : INT:S:17 [:S:12 FACT:16 TERM:15 EXPR:7 7 : ]:S:18 +:S:8 8 : INT:S:17 [:S:12 FACT:16 TERM:9 9 : ]:R:1 +:R:1 *:S:10 10 : INT:S:17 [:S:12 FACT:11 11 : ]:R:3 +:R:3 *:R:3 12 : INT:S:17 [:S:12 FACT:16 TERM:15 EXPR:13 13 : ]:S:14 +:S:8 14 : ]:R:5 +:R:5 *:R:5 15 : ]:R:2 +:R:2 *:S:10 16 : ]:R:4 +:R:4 *:R:4 17 : ]:R:6 +:R:6 *:R:6 18 : END:R:5 +:R:5 *:R:5 19 : END:R:6 +:R:6 *:R:6 20 : END:R:4 +:R:4 *:R:4 21 : END:R:2 +:R:2 *:S:4
注意してほしいことがあり、Reduceの出力はEND:R:1みたいになっていますが、
番号の1は遷移先ではなく、規則の通し番号です。
続きます
Common LispでLALR(1)のparserを作る2
前回:Common LispでLALR(1)のparserを作る1 - nptclのブログ
【変更】first-parseを修正しました。
1. 続きです
Common Lispでひたすらparserを作っていきます。
前回は、shift, reduceについて解説しました。
今回はLR(1)をひたすら作っていきます。
ここらへんから、本当にひたすら作るだけになります。
作って作って作る作業ばかりなので、プログラミング持久走みたいになります。
飽きますし疲れますので注意。
2. アナフォリックマクロ
すみません、アナフォリックマクロを使わせて下さい。
これ本当に便利なんです。
基本的にはCommon Lisp標準の機能しか使わないようにしてるんですが、
こいつは使いたいです。
アナフォリックマクロってなんだよという前に、 まずは定義を示します。
(defmacro aif (expr then &optional else) `(let ((it ,expr)) (if it ,then ,else))) (defmacro awhen (expr &body body) `(aif ,expr (progn ,@body))) (defmacro aprog1 (expr &body body) `(let ((it ,expr)) (prog1 it ,@body))) (defmacro aif2 (expr then &optional else) (let ((g (gensym))) `(multiple-value-bind (it ,g) ,expr (if ,g ,then ,else)))) (defmacro awhen2 (expr &body body) `(aif2 ,expr (progn ,@body)))
aif, awhen, aprog1は、普通のアナフォリックマクロです。
if文で、条件判定に使われた値をitという変数で参照できるというもの。
つまり、
(if expr then)
みたいな文が
(let ((it expr)) (if it then))
のように展開されます。
aif2とawhen2はちょっと複雑です。
if文がtrueと判定されるのは、条件式の第一返却値ではなく、
第二返却値がtrueのときです。
これはいろんな流儀があります。
有名なものだと、ifの判定は、(or 第一返却 第二返却)で行うものがあります。
今回は第二返却だけに注目しています。
そしてitに束縛されるのは、第一返却値です。
itの束縛については、多分どのaif2においても第一返却値で共通だと思います。
つまり、
(aif2 expr then)
という文は、
(multiple-value-bind (it #:check) expr (if #:check then))
になります。
ちょっとややこしいかもしれませんが、今後ずっと使っていきます。
3. CLOSURE
さあLR(1)を作りましょう!
まずはCLOSUREを作ります。
こいつが何なのか良くわかりませんが、難しいことは後で考えます。
;; CLOSURE(I) ;; repeat ;; foreach ([A -> alpha . B beta, term-a] in I) ;; foreach ([B -> gamma] in *rule*) ;; foreach (term-b in FIRST(beta term-a)) ;; add [B -> . gamma, term-b] to I; ;; until no more items are added to I; ;; return I;
Common Lispで作ります。
結構大変ですががんばりましょう。
まず、繰り返しが4つもあることに注目します。
repeat, foreach, foreach, foreachの4つです。
repeatには、untilが対応しており、
「Iに何も追加されなかったらループ終了」とのこと。
3つのforeachのあとにはaddという命令があるのですが、
この処理は結構複雑です。
まずはrepeatを処理したいので、
追加が生じたかどうかはaddの返却値によって判定したいと思います。
最初はこんな感じで作成してみます。
(defun closure-parse (list) (aif2 (closure-foreach list) (closure-parse it) list))
closure-parse関数がCLOSUREそのものになります。
CLOSUREのrepeat/untilを実現するために、再帰呼出のつくりになっています。
これから作成するclosure-foreachという関数の
第二返却値がtならば、自分自身であるclosure-parse関数を呼び出すというものです。
closure-foreachを示します。
(defmacro dobind (bind expr &body body) (let ((g (gensym))) `(dolist (,g ,expr) (destructuring-bind ,bind ,g ,@body)))) (defun closure-foreach (list) (let (update) (dobind (b beta term-a) (closure-filter list) (dolist (gamma (closure-grammar b)) (dolist (term-b (closure-first beta term-a)) (awhen2 (closure-add b gamma term-b list) (setq list it update t))))) (values list update)))
元の文にあるforeach, foreach, foreachが、
dobind, dolist, dolistに対応します。
見た目をそろえるためだけに、dobindというマクロを作成しました。
ここで呼ばれている下記の関数を一つずつ説明していきます。
closure-filterclosure-grammarclosure-firstclosure-add
やっていることは、とにかくlistに何かを追加しようとしています。
新しい要素が追加できたらupdateをtにして、
呼び出し元であるclosure-parseにもう一度実行してほしいとお願いします。
それでは、最初に関数closure-filterから見ていきましょう。
元の文は次の個所に対応します。
;; foreach ([A -> alpha . B beta, term-a] in I) (dobind (b beta term-a) (closure-filter list) ...)
ここはかなり丁寧に説明する必要があります。
まず引数のIというのは何らかの集合を表します。
集合とは、順不同の要素が集まったものです。
その集合Iの中に、
[A -> alpha . B beta, term-a]
に対応するような何かが入っているということです。
表記法に独特なルールがあります。
alpha, beta (あとgammaも)というのは0個以上の記号の列を意味します。
A, Bは、たった1つの非終端記号を意味します。
普通の規則であれば、
left -> right
みたいな形になりますが、LR(1)では、rightを二つの部分に分けます。
つまり、
left -> alpha . beta
みたいな感じになります。
alphaとbetaは記号の列なので、Common Lispではリストとして表現します。
ドット.は、現在処理中の場所を意味しています。
さらに、LR(1)の、(1)という部分は1つの先読みを意味しているわけですが、
先読みした終端記号をaとした場合、
left -> alpha . beta, a
みたいな感じに表します。
この[left -> alpha . beta, a]みたいな形のやつが、
集合Iにいっぱい入っているわけです。
上記のようにsymbolの列をそのまま格納してもいいのですが、
構造体を作って管理しましょう。
(defstruct grammar left alpha beta ahead) (defun grammar-instance (left alpha beta ahead) (make-grammar :left left :alpha alpha :beta beta :ahead ahead)) (defun grammar-instance-rest (left alpha beta &rest ahead) (grammar-instance left alpha beta ahead))
grammarが構造体です。
grammar-instanceとgrammar-instance-restは、構造体を作成するための関数です。
leftは左辺、alphaとbetaは右辺、
そしてaheadは先読みの終端記号を格納した集合です。
つまりは次のようにあらわされます。
left -> alpha . beta, ahead
aheadは、本来たった1つの終端記号なのですが、
例えば下記のように
left -> alpha . beta, a left -> alpha . beta, b
left, alpha, betaが同じものの場合は、
まとめて下記のようにあらわすと便利です。
left -> alpha . beta, a/b
ということで、aheadはリストで管理します。
例えば、
expr -> expr + . term, a/b
のような文を表す場合は、
(grammar-instance-rest 'expr '(expr +) '(term) 'a 'b)
のようになります。
ではforeach文に戻りましょう。
[A -> alpha . B beta, term-a]
つまりは、集合Iの中にある文のうち、ドット右側が、
(grammar-beta x) == (B . beta)
の形になっているものを全て抜き出せという意味です。
今回、A, alphaに該当する部分は使いませんので、
B, beta, term-aの3つの値を
foreachで割り当ててループします。
それでは作成してみましょう。
(defun closure-filter (list) (let (root) (dolist (inst list) (awhen (grammar-beta inst) (destructuring-bind (b . beta) it (when (non-terminal-p b) (dolist (ahead (grammar-ahead inst)) (push (list b beta ahead) root)))))) root))
わりとそのまま作成しています。
まず集合Iであるlistをdolistで回します。
grammar-betaが(B . beta)の形なら、(B beta ahead)をpushします。
返却値は集合なので、順番は適当で問題ありません。
それでは2番目のforeachを見てみます。
;; foreach ([B -> gamma] in *rule*) (dolist (gamma (closure-grammar b)) ...)
これは全然難しくありません。
いまBは分かっているので、対応する規則の右辺rightを求めるだけです。
(defun closure-grammar (b) (let (root) (dolist (inst *rule*) (when (eql (rule-left inst) b) (push (rule-right inst) root))) root))
最後のforeachを見てみます。
;; foreach (term-b in FIRST(beta term-a)) (dolist (term-b (closure-first beta term-a)) ...)
ただ単にFIRSTという関数を呼んでいるだけです。
FIRSTはちょっと難しかったので詳しく見ていきます。
FIRST(X)は、最初に遭遇する終端記号を返却します。
aが終端記号のとき、FIRST(a)はそのままaが返却されるわけですが、
返却は集合であることを注意してください。
つまりFIRST(a) -> {a}です。
なぜ集合になるのかというと、
X -> a X -> b
のようなときは、FIRST(X)に、aとbのどちらにも遭遇する可能性があるからです。
最初に遭遇した終端記号の集合ということなので、 例えば下記のような場合、
X -> A B C
FIRST(X)は、もしFIRST(A)に返却値がある場合は
FIRST(X) -> FIRST(A)
です。
しかし、FIRST(A)が空の場合は、次にFIRST(B)を同様に調べます。
FIRST(B)に返却値があればそれが返却になりますが、
無かったらFIRST(C)を調べるという動作になります。
これってどうやって作ればいいと思いますか。
普通に再帰で実装することを考えていたのですが、
例えば
expr -> expr + term
みたいな場合って、FIRST(expr)を調べると
すぐにFIRST(expr)に遭遇するので無限ループになってしまうんですよね。
【変更】first-parseを修正しました。
もし自分自身に遭遇した場合は、その規則は無視して次の規則を調べることにします。
あと、今回の実装ではFIRSTの引数がリストなので、
まずはリストの処理から見ていきましょう。
(defun first-parse (list) (when list (destructuring-bind (car . cdr) list (or (first-symbol car) (first-parse cdr)))))
引数のリストを順番に処理していき、
もしfirst-symbol関数に返却値があったら全体を終了させます。
次にfirst-symbol関数を見てみます。
(defun first-symbol (x) (cond ((terminalp x) (list x)) ((non-terminal-p x) (first-nonterm x)) (t (error "Invalid symbol, ~S." x))))
もし引数が終端記号なら、それを返却して終わりです。
非終端記号なら、first-nontermを呼び出します。
余談ですが、ここのエラーは誤字脱字を指摘してくれるので便利です。
first-nontermを見てみます。
(defun first-nonterm (x) (let (root) (dolist (right (first-rule x)) (dolist (y (first-right x right)) (pushnew y root))) root))
二つのdolistがあります。
最初のfirst-ruleは、非終端記号xから該当する規則の集合を求めます。
二つ目のfirst-rightはFIRST(right)の結果を返却します。
yは終端記号であり、pushnewで重複がないように収集します。
first-ruleとfirst-rightを順番に見ていきます。
(defun first-rule (x) (let (list) (dolist (y *rule*) (when (eql x (rule-left y)) (push (rule-right y) list))) list))
first-ruleは難しくありません。
引数の非終端記号xと、規則のleftが等しいものの
rightをリストとして返却するだけです。
(declaim (ftype function first-symbol)) (defun first-right (x right) (dolist (y right) (when (eql x y) (return nil)) (aif (first-symbol y) (return it))))
やっていることはFIRST(right)を求めるだけなのですが、
もし自分自身の非終端記号に遭遇した場合はnilを返却します。
つまりは
expr -> expr + term
のような場合です。
nilを返却するため、次の規則を調べるように指示します。
これでfirst-parse関数は完成しましたので、元の文に戻ります。
;; (dolist (term-b (closure-first beta term-a)) (defun closure-first (beta term) (or (first-parse beta) (list term)))
foreachで呼ばれていたclosure-firstです。
もともとの文はFIRST(beta term-a)なので、
まずfirst-parseでFIRST(beta)を求め、
もし値が無かったら(list term)を返却しています。
ここまでで、repeatと3つのforeachの説明は完了しました。
次はclosure-addです。
;; add [B -> . gamma, term-b] to I; (awhen2 (closure-add b gamma term-b list) (setq list it update t))
もしclosure-add関数で値が追加された場合は、
listを更新し、updateにtを代入します。
第二返却値がnilの場合は何もしません。
closure-addはlistに追加するだけなのですが、
無条件に追加するのではなく
pushnewのように既に追加されているかどうかを調べる必要があります。
また、単にlistにpushするのではなく、
left, alpha, betaが同一の要素が存在する場合は、
aheadの集合にpushnewしなければなりません。
その辺を全部考慮して作っていきます。
(defun closure-add (left beta term list) (aif (closure-add-find left beta list) (closure-add-ahead it term list) (closure-add-list left beta term list)))
まずはclosure-add-findで要素が存在するかどうかを調べます。
存在する場合はclosure-add-aheadを呼びます。
存在しない場合はclosure-add-listを呼びます。
順番にclosure-add-findから見てきます。
(defun closure-add-find (left beta list) (dolist (inst list) (and (equal (grammar-left inst) left) (equal (grammar-alpha inst) nil) (equal (grammar-beta inst) beta) (return inst))))
ただ検索しているだけですが、
leftとbetaだけをequal判定し、alphaはnilかどうかを調べています。
どうしてかというと、追加する内容が次のようなものだからです。
[B -> . gamma, term-b]
alphaが存在しないのです。
aheadを無視しているのは次の処理で分岐させるためです。
ahead以外のleft, alpha, betaの3つが一致することを、
「コアが等しい」というらしいです。
この辺の話はLALR(1)のときによく出てきます。
それでは、コアが等しい場合のclosure-add-aheadを見ていきます。
(defun closure-add-ahead (inst term list) (unless (member term (grammar-ahead inst)) (push term (grammar-ahead inst)) (values list t)))
やっていることはgrammar-aheadにpushnewするだけなのですが、
もしpushに成功した場合は、
(values list t)を返却しないと正しく更新されません。
unlessやらmemberやらで存在確認しているのはそのためです。
次は等しいコアが見つからなかった場合のclosure-add-listです。
(defun closure-add-list (left beta term list) (let ((v (grammar-instance-rest left nil beta term))) (values (cons v list) t)))
こちらは単純にpushするだけです。
ずいぶん長くなりましたが、以上でCLOSUREの作成は終わりです。
4. 試しに実行する
そもそもCLOSUREってなんなのって話ですが、
集合Iのドットの位置から非終端記号を経由して、
たどれるところ全部たどって行った場合の
新しい集合を返却する機能です。
正規表現をやったことある人なら
NFAからDFAに変換するときに、
epsを全部たどるみたいなことをしたことがあるかもしれません。
つまりそれです。
これからCLOSUREを使って、構文解析のDFAを作ろうとしています。
試しに実行してみましょう。
まずは初期状態の集合を作ります。
最初の文は下記の通り。
#:start -> . expr, #:end
#:startは、開始を表す値*start-symbol*です。
#:endは、EOFを表す値*end*です。
exprは、parse-startで設定した値*start*です。
「. expr」で分かるように、初期状態なのでalphaはnilです。
実行してみましょう。
(parse-terminal + * [ ] int) (parse-start expr) (parse-rule expr -> expr + term) (parse-rule expr -> term) (parse-rule term -> term * fact) (parse-rule term -> fact) (parse-rule fact -> [ expr ]) (parse-rule fact -> int) (let* ((left *start-symbol*) (beta (list *start*)) (ahead *end*) (x (grammar-instance-rest left nil beta ahead))) (format t "~S~%" x) (format t "~S~%" (closure-parse (list x))))
結果は下記の通り。
#S(GRAMMAR :LEFT #:START :ALPHA NIL :BETA (EXPR) :AHEAD (#:END)) (#S(GRAMMAR :LEFT FACT :ALPHA NIL :BETA (INT) :AHEAD (* + #:END)) #S(GRAMMAR :LEFT FACT :ALPHA NIL :BETA ([ EXPR ]) :AHEAD (* + #:END)) #S(GRAMMAR :LEFT TERM :ALPHA NIL :BETA (FACT) :AHEAD (* + #:END)) #S(GRAMMAR :LEFT TERM :ALPHA NIL :BETA (TERM * FACT) :AHEAD (* + #:END)) #S(GRAMMAR :LEFT EXPR :ALPHA NIL :BETA (TERM) :AHEAD (+ #:END)) #S(GRAMMAR :LEFT EXPR :ALPHA NIL :BETA (EXPR + TERM) :AHEAD (+ #:END)) #S(GRAMMAR :LEFT #:START :ALPHA NIL :BETA (EXPR) :AHEAD (#:END)))
次は状態遷移表をつくります。
続きます
Common LispでLALR(1)のparserを作る1
1. はじめに
Common LispでLALR(1)のparserを作りたくなりました。
ここでは、ただひたすらparserを作っていきます。
テストコードですが完成版を先に置いておきます。
https://github.com/nptcl/parser/blob/main/blog/parser.lisp
2. parserの説明
parserは、構文解析器(syntax analyzer)と呼ばれます。
種類がいろいろありますが、ここで作るのは次の2つ。
- LR(1)
- LALR(1)
いちおう説明を混ぜつつ作っていく予定ですが、
理解したいだけなら参考資料を見た方が早いです。
というか、私自身全然理解できてません。
見たサイトを紹介します。
LR(1)パーサジェネレータを自作して構文解析をする 第1回:かんたん構文解析入門
http://tatamo.81.la/blog/2016/12/22/lr-parser-generator-implementation/
日本語で分かりやすく書かれていてよかったです。2016年度コンパイラ理論の講義資料
http://www.sakurai.comp.ae.keio.ac.jp/classes/2016Compiler.html
http://www.sakurai.comp.ae.keio.ac.jp/classes/DENDAI/2016/08LR.pdf
大学の講義資料のようで、難しかったけどずっと見てました。LR構文解析
https://www.slideshare.net/ichikaz3/lr-parsing
これ本当に良かったです。
絶対見た方がいいです。
3. token
まずはtokenについて。
tokenとは、parserの前段である字句解析が出力するものです。
でも今回は字句解析を作成しません。
そのかわり、Common Lispのreaderを使います。
字句解析は、入力に文字列を受け取り、tokenの列を返却します。
たとえば、
10 + 20 + 30
という文字列を受け取ったら、
INT PLUS INT PLUS INT
のようなtokenの列を返却します。
INTは構造体だと思ってください。
本来であればちゃんと、10とか20のような値を取り出せます。
でも今回はtokenをCommon Lispのsymbolで表したいと思います。
上記の例の場合、
(int + int + int)
のような列でいいのではないでしょうか。
4. 文法
文法を定義しましょう。
文法は次の3つくらいから成り立ちます。
- 終端記号 (terminal symbol)
- 規則 (rule)
- 開始記号 (start symbol)
順番に作っていきます。
4.1 終端記号
終端記号とは、それ以上展開がない記号の事です。
設定は、次のように行うことを考えます。
(parse-terminal + * [ ] int)
これは、+, *, [, ], intの5つの記号を終端記号に設定しています。
コードは次の通り。
(defvar *terminal* nil) (defun read-terminal (cdr) (dolist (x cdr) (pushnew x *terminal*))) (defmacro parse-terminal (&rest args) `(read-terminal ',args))
ただ、*terminal*という変数にpushするだけです。
あと、read-terminalをparse-terminalで囲っているのは、
ただ、symbolをquoteするのが面倒だっただけです。
いやなら直接read-terminalを使ってください。
終端記号かどうかの判定は、*terminal*に存在するかどうかを調べます。
(defun terminalp (x) (and (member x *terminal*) t))
4.2 規則
規則とは、例えば次のようなものです。
expr -> expr + term expr -> term term -> term * fact term -> fact fact -> ( expr ) fact -> int
これをLispの式で表します。
(parse-rule expr -> expr + term) (parse-rule expr -> term) (parse-rule term -> term * fact) (parse-rule term -> fact) (parse-rule fact -> [ expr ]) (parse-rule fact -> int)
parse-ruleは、規則を制定するときに使います。
->は、左辺と右辺を区切る記号です。
ちょっと困ったのが[ expr ]です。
本当は( expr )であり、数式をまとめるやつなんですが、
()にしてしまうと、Lispのreaderが色々やってしまうので構文解析ができません。
仕方がなく[]のカッコにしました。
今回は説明のためだけの対処なので、
もし本番を作る場合は、そもそもtokenにsymbolなんか使わずに、
classやらstructureやら使ってください。
ひとまずこれでいきます。
規則は、専用の構造体を用意します。
(defstruct rule index left right accept)
例えば次の規則の場合。
A -> B C D
leftにはAが、rightには、(B C D)が入ります。
indexは通し番号が入ります。
acceptは通常nilですが、開始記号の場合はtを入れます。
これはあとあとの処理で役立ちます。
まずは構造体のインスタンスを作成する処理を示します。
(defvar *rule-index* 0) (defun rule-instance (left right &optional accept) (prog1 (make-rule :index *rule-index* :left left :right right :accept accept) (incf *rule-index*)))
rule-instanceは、leftとrightを値に受け取り、インスタンスを生成します。
acceptもオプションで設定可能です。
indexは自動で設定されます。
規則はどこかにまとめて保存しておく必要があります。
今回は、*rule*という変数にリストとして保存することにします。
(defvar *rule* nil) (defun read-rule (cdr) (destructuring-bind (left check . right) cdr (unless (eq check '->) (error "Invalid rule, ~S." cdr)) (unless right (error "right value error, ~S." cdr)) (push (rule-instance left right) *rule*))) (defmacro parse-rule (&rest args) `(read-rule ',args)) (defun non-terminal-p (x) (and (member x *rule* :key #'rule-left) t))
read-rule関数は、なにやらごちゃごちゃしていますが、
ただインスタンスを*rule*にpushしてるだけです。
non-terminal-pは、非終端記号かどうかを調べます。
4.3 開始記号
最後に開始記号です。
(defvar *start-symbol* (make-symbol "START")) (defvar *start* nil) (defun read-start (cdr) (destructuring-bind (start) cdr (when *start* (error "start already exist, ~S." *start*)) (push (rule-instance *start-symbol* (list start) t) *rule*) (setq *start* start))) (defmacro parse-start (&rest args) `(read-start ',args))
何をしているのかというと、
(parse-start expr)
が実行されたら、*start*変数にexprを保存したあと、
(parse-rule #:start -> expr)
という規則を*rule*に追加します。
#:startはgensymになっているため、
仮にstartという非終端記号が現れても競合しません。
4.4 まとめ
例ですが、今後使っていく文法を下記に示します。
(parse-terminal + * [ ] int) (parse-start expr) (parse-rule expr -> expr + term) (parse-rule expr -> term) (parse-rule term -> term * fact) (parse-rule term -> fact) (parse-rule fact -> [ expr ]) (parse-rule fact -> int)
それっぽくなってきました。
入力はリストになります。
例えば次のようになると思います。
(int * int + int)
5. 構文解析器
まずは、最終的に何を作るのかを解説します。
構文解析器は、
- tokenの列を入力として受け取り
- stackを用いて文法を判定します
それでは、まずは入力を何とかしましょう。
(defvar *end* (make-symbol "END")) (defvar *input*) (defun set-input (x) (setq *input* x)) (defun pop-input () (if *input* (pop *input*) *end*)) (defun top-input () (if *input* (car *input*) *end*))
set-inputで入力の列を設定します。
pop-inputで入力から一つ値を取り出します。
top-inputは先頭の入力を返却しますが、取り出しはしません。
例として、aaa + bbbという入力を設定します。
(set-input '(aaa + bbb))
入力をpopしてみましょう。
(pop-input) -> AAA (pop-input) -> + (pop-input) -> BBB (pop-input) -> #:END (pop-input) -> #:END
入力が終わったら、#:ENDというgensymが出力されるのがわかります。
次は、処理の中枢となるスタックを作ります。
(defvar *stack* nil) (defun push-stack (x) (push x *stack*)) (defun pop-stack () (unless *stack* (error "pop-stack error")) (pop *stack*)) (defun top-stack () (unless *stack* (error "top-stack error")) (car *stack*)) (defun init-stack () (setq *stack* nil))
ただpushとpopを隠蔽しているだけです。
作成したinputとstackを使い、次の2つの処理を実装します。
shift処理reduce処理
このshiftとreduceという処理が、構文解析でとても大切なものになります。
この2つをちゃんと覚えておいて下さい。
shiftは、たんに入力をstackにpushするだけです。
reduceは、文法から非終端記号に変換します。
実際にやってみて説明します。
まずはshiftから。
(defun shift-test () (push-stack (pop-input)))
これはとても簡単な処理です。
動作確認なんかもしたいので、stackとinputを出力する関数を用意します。
(defun output-stack-input () (format t "~S~30T~S~%" (reverse *stack*) *input*))
inputだけを設定した時の動作を見てみましょう。
* (set-input '(int * [ int + int ])) * (output-stack-input)
出力結果は下記の通り。
NIL (INT * [ INT + INT ])
stackがNILで、inputが(INT * [ INT + INT ])という意味です。
この状態でshiftを1回行うと、先頭のINTがstackに移動します。
* (shift-test) * (output-stack-input) (INT) (* [ INT + INT ])
さらにもう一度。
* (shift-test) * (output-stack-input) (INT *) ([ INT + INT ])
次にreduceを見ていきましょう。
reduceは、引数の規則を適用して、stackの状態を変える操作です。
(defun reduce-call (left right) (let (list) (dolist (ignore right) (push (pop-stack) list)) (unless (equal right list) (error "reduce error, ~S /= ~S." right list))) (push-stack left)) (defun reduce-test (x) (destructuring-bind (left check . right) x (unless (and (eq check '->)) (error "operator error, ~S." x)) (unless right (error "right value error, ~S." x)) (reduce-call left right)))
何やら複雑そうですが、例えば下記の実行を考えます。
(reduce-test '(fact -> int))
reduce-test関数は、単純に次のような実行に変えるだけです。
(reduce-call 'fact '(int))
reduce-callは少し複雑ですが、大したことはしていません。
stackの先頭にあるintをfactに置き換えているだけです。
次のような状況を考えてみましょう。
* (set-input '(int * [ int + int ])) * (shift-test) * (output-stack-input) (INT) (* [ INT + INT ])
ここで、(fact -> int)を用いてreduceしてみます。
* (reduce-test '(fact -> int)) * (output-stack-input) (FACT) (* [ INT + INT ])
stackのintがfactに変わったのが分かります。
もう少し複雑な例としてはこんな感じ。
* (output-stack-input) ([ [ EXPR + TERM) (+ INT + INT ] ]) * (reduce-test '(expr -> expr + term)) * (output-stack-input) ([ [ EXPR) (+ INT + INT ] ])
stack上のexpr + termが、exprにreduceされました。
さて、shiftとreduceの動作が分かったところで、
(int * [ int + int ])の構文解析をしてみましょう。
shiftとreduceを順番に実行して、
最終的にstartであるexprにまでreduceできたら
構文解析は終了です。
ではどういう順番で実行したらいいでしょうか?
テストのために、まずはoutput-stack-inputを合わせて実行する、
shift*とreduce*を定義します。
(defun shift* () (shift-test) (output-stack-input)) (defun reduce* (x) (reduce-test x) (output-stack-input))
自分が適当に実行してみた結果を下記に示します。
(set-input '(int * [ int + int ])) (output-stack-input) (shift*) (reduce* '(fact -> int)) (reduce* '(term -> fact)) (shift*) (shift*) (shift*) (reduce* '(fact -> int)) (reduce* '(term -> fact)) (reduce* '(expr -> term)) (shift*) (shift*) (reduce* '(fact -> int)) (reduce* '(term -> fact)) (reduce* '(expr -> expr + term)) (shift*) (reduce* '(fact -> [ expr ])) (reduce* '(term -> term * fact)) (reduce* '(expr -> term))
実行結果は下記の通り。
NIL (INT * [ INT + INT ]) (INT) (* [ INT + INT ]) (FACT) (* [ INT + INT ]) (TERM) (* [ INT + INT ]) (TERM *) ([ INT + INT ]) (TERM * [) (INT + INT ]) (TERM * [ INT) (+ INT ]) (TERM * [ FACT) (+ INT ]) (TERM * [ TERM) (+ INT ]) (TERM * [ EXPR) (+ INT ]) (TERM * [ EXPR +) (INT ]) (TERM * [ EXPR + INT) (]) (TERM * [ EXPR + FACT) (]) (TERM * [ EXPR + TERM) (]) (TERM * [ EXPR) (]) (TERM * [ EXPR ]) NIL (TERM * FACT) NIL (TERM) NIL (EXPR) NIL
うまくいきました!
終了です!
とはなりません。
そもそもshift*とreduce*の実行は、
どうやって決めたの?ってなりませんか?
自分が適当に実行してみたと書きましたが、
本当に適当にというか、試行錯誤してやった結果です。
しかしそんなの本番で使えるわけがありません。
本来であれば、入力に応じて、
shiftとreduceの実行内容は自動的に決まるものなのです。
そして、その決める方法をLR(1)とか、LALR(1)と呼びます。
ここまででshiftとreduceの動作は理解できたと思います。
ここからは、LR(1)法を用いて、shiftとreduceの実行内容を決める方法を見ていきます。
続きます
nptでsoファイルを読み込む
前回nptでDLLファイルを読み込む - nptclのブログの続きです。
前の投稿ではnptにDLLファイルを読み込ませましたが、
soファイルもやりたいな、ということでやりました。
個人的にはsoファイルの作成は初めてなので、 いろいろと勉強になりました。
1. nptのコンパイルから
nptのコンパイルの方法が変わります。
次のオプションをつけてください。
- nptコンパイル時
-DLISP_DYNAMIC_LINK
リンク時は-ldlが必要になるかと思います。
コンパイルスクリプトは修正して普通に利用できるようにしています。
利用可能かどうかは次のようにして調べます。
$ npt --version-script | grep dynamic-link dynamic-link true
2. soファイルの作成
それではsoファイルを作りましょう。
やり方はDLLと同じですが、詳しく書いていきます。
下記のファイルを用意してください。
npt/develop/dlfile/lispdl.clispdl.h
ひな形を示します。
#include "lispdl.h" int lisp_dlfile_main(lisp_dlfile_array ptr) { return lisp_dlfile_update(ptr); }
もし初期化と解放処理が必要な場合は、次のようにするそうです。
#include "lispdl.h" void init(void) __attribute__((constructor)); void fini(void) __attribute__((destructor)); void init(void) { /* 初期化 */ } void fini(void) { /* 解放 */ } int lisp_dlfile_main(lisp_dlfile_array ptr) { return lisp_dlfile_update(ptr); }
lisp_dlfile_main関数は、nptが真っ先に呼び出す初期化用の関数です。
この関数でやることは、lisp_dlfile_update関数を呼び出すだけです。
lisp_dlfile_update関数は、呼び出し元のnpt環境から色んな機能をso内部に持ってくる命令です。
nptはsoファイルを読み込むと
まずはlisp_dlfile_main関数を呼び出そうとします。
#includeしているlispdl.hは、
amalgamationが提供するlisp.hのsoバージョンなので、
nptの説明書に記載されている方法で開発できます。
単に"Hello"という文字列を返却する関数hello_を作ってみます。
公開する関数は、必ず脱出関数にしてください。
#include "lispdl.h" int lisp_dlfile_main(lisp_dlfile_array ptr) { return lisp_dlfile_update(ptr); } int hello_(addr rest) { addr control, x; lisp_push_control(&control); x = Lisp_hold(); lisp_string8_(x, "Hello"); lisp_set_result_control(x); return lisp_pop_control_(control); }
終わりです。
ではコンパイルをしましょう。
上記のファイルがaaa.cであるとします。
$ cc -fPIC -shared -o aaa.so lispdl.c aaa.c
いろいろと知らない引数が出てきました。
-fPICは再配置可能なコードを出すんだそうです。
-fpicもあるらしいですが、上記のように大文字にしておけば安全です。
-sharedは、soファイル出力用だそうです。
lispdl.cは忘れないでくださいね。
忘れると、後でなんでdlfileで失敗するんだって延々と悩むことになります。
成功すれば、aaa.soファイルが出力されます。
3. nptで実行
nptを起動してください。
同じディレクトリにaaa.soをコピーしてください。
まずは操作が面倒なのでnpt-systemパッケージをuseします。
* (use-package 'npt)
soを読み込むには、dlfile関数を使用します。
dlfileの第一引数にopenを指定します。
* (setq x (dlfile 'open "./aaa.so")) #<PAPER 0 ...>
Windows版とは違い、"aaa.so"ではなく、
"./aaa.so"のようにしないと失敗しました。
そういえば大昔はカレントディレクトリ.がPATHに入ってたの知ってますか?
セキュリティホールになったので廃止されたんです。
それを思い出してしまいました。
あとはWindows版と同じです。
* (setq y (dlfile 'call x "hello_")) #<PAPER 0 ...> * (dlcall y) "Hello"
soの開放は次の通り。
* (dlfile 'close x)
4. その他の機能
DLLとsoのどちらも共通した話のなのですが、
openして放置したらそれはリークです。
例えばこんな感じ。
* (dlfile 'open "./aaa.so") #<PAPER 0 #x80174ee28> * (dlfile 'open "./aaa.so") #<PAPER 0 #x80174f8d8> * (dlfile 'open "./aaa.so") #<PAPER 0 #x801750388> * (dlfile 'open "./aaa.so") #<PAPER 0 #x801750e38> *
こうなると、プロセスを終了させない限り
aaa.soの残骸がメモリに残り続けるわけです。
それはちょっとどうかと思ったので、一応救済措置を設けました。
dlfileにlistを指定して下さい。
* (dlfile 'list) (#<PAPER 0 #x801750e38> #<PAPER 0 #x801750388> #<PAPER 0 #x80174f8d8> #<PAPER 0 #x80174ee28>)
こんな感じで、closeされていない、open中のdlfileの一覧が得られます。
もし(dlfile :close x)でcloseされた場合は、この一覧に出てきません。
リークに困っているなら、このリストにあるオブジェクトをcloseしていけばいいわけです。
それにしたって情報がなさすぎなので、
せめて何のファイルをopenしたのかくらいの情報を得る命令を追加しました。
dlfileにinfo指定すると、引数の情報を出力します。
例えばこんな感じ。
* (setq x (dlfile 'open "./aaa.so")) #<PAPER 0 #x801752dd0> * (dlfile 'info x) #P"./aaa.so" T
第一返却値は、dlfileオブジェクトの場合はパス名を返却します。
第二返却値は、closeされていなかったらTを返却します。
何も考えずに全部閉じたい場合は次のようにしてください。
* (mapcar (lambda (x) (dlfile 'close x)) (dlfile 'list)) (T T T T T)
全部閉じた場合はこんな感じになります。
* (dlfile 'list) NIL
nptでDLLファイルを読み込む
1. はじめに
nptのWindows版で、DLLを読み込む機能を作りました。
FFIでは無いので注意。
npt用にDLLを作成すると読み込めるというものです。
【追記】soも作りました! nptでsoファイルを読み込む - nptclのブログ
npt for Windowsは、なんとなくうまく動いているように見えます。
さらにDLLを呼び出せるようにできれば、
Windowsで簡単な仕事をさせることができるのではと思いました。
もうちょっとウィンドウの操作をちゃんと作ればいいような気がしています。
履歴とかコピーとか、あとプロンプトの操作もアップデートして行きたいです。
2. DLLの作成
まずはDLL作成から。
下記のファイルを用意してください。
npt/develop/dlfile/lispdl.clispdl.h
これらのファイルを用いて、DLLを作成していきます。
Visual Studioでもgccでもなんでも良いので、
DllMainを作成できる環境を用意して下さい。
注意点を先に示しますが、「呼出規約」をnpt本体と合わせる必要があります。
Windows上では、だいたいcdeclとstdcallの二種類の呼出規約が混ざって存在しています。
呼出規約ってなんなのって話ですが、
関数を呼ぶときと呼ばれるときにどういう動きにするかを
CPUの動作レベルで決めたインターフェイスの事です。
ちょっと詳しく説明します。
Microsoftが提供しているCコンパイラはCL.EXEだと思うのですが、
このコンパイラで何も指定をしなかった場合はcdeclが使用されます。
バイナリで配布しているnpt32.exeとnpt64.exeもcdeclです。
nptがcdeclならDLLで公開する関数もcdeclにしてください。
ネットを色々見ると、DLLの関数はみんなstdcallか
あるいはCALLBACKみたいなマクロを用いています。
そうする理由は、Windowsが標準で提供してるAPIが全部stdcallだからです。
CALLBACKとかWINAPIなどのマクロも確か全部stdcallのはず。
だからDLLはstdcallしか作れないのかとばかり思ってました。
どうもそんなことはないようです。
cdeclで公開してください。
それが嫌ならば、npt本体をstdcallで作成し直してください。
(もしかしたらnptをstdcallで作るの無理かも)
cdeclとstdcallは一見して似通っているので
適当に設定しても動くことがあります。
でも、これがとんでもないバグというか、問題を引き起こします。
絶対に合わせましょう。
ついでに言っておきますが、ビット数も合わせてください。
nptが64bitなら、DLLも64bitでコンパイルする必要があります。
それでは、簡単な例を示します。
#include "lispdl.h" #include <Windows.h> BOOL WINAPI DllMain(HINSTANCE hInst, DWORD fdwReason, LPVOID lpReserved) { switch (fdwReason) { case DLL_PROCESS_ATTACH: case DLL_PROCESS_DETACH: case DLL_THREAD_ATTACH: case DLL_THREAD_DETACH: return TRUE; } } __declspec(dllexport) int __cdecl lisp_dlfile_main(lisp_dlfile_array ptr) { return lisp_dlfile_update(ptr); }
DllMain関数は何もしてないので説明は不要かと思います。
lisp_dlfile_main関数は、nptが真っ先に呼び出す初期化用の関数です。
呼出規約を__cdeclで指定しています。
先ほど説明した通り、npt本体がstdcallの場合は、__stdcallを指定してください。
この関数でやることは、lisp_dlfile_update関数を呼び出すだけです。
lisp_dlfile_update関数は、呼び出し元のnpt環境から色んな機能をDLL内部に持ってくる命令です。
後で説明しますが、nptはDLLを読み込むと
まずはlisp_dlfile_main関数を呼び出そうとします。
【参考】以前はlisp_dlfile_mainではなく、lisp_dllmainという名前でした。
【参考】いちおうlisp_dllmainでも、今のところ動きます。
これでDLLを作成する準備ができました。
なにか作ってみましょう。
#includeしているlispdl.hは、
amalgamationが提供するlisp.hのDLLバージョンなので、
nptの説明書に記載されている方法で開発できます。
単に"Hello"という文字列を返却する関数hello_を作ってみます。
公開する関数は、必ず脱出関数にしてください。
__declspec(dllexport) int __cdecl hello_(addr rest) { addr control, x; lisp_push_control(&control); x = Lisp_hold(); lisp_string8_(x, "Hello"); lisp_set_result_control(x); return lisp_pop_control_(control); }
順に説明します。
__declspec(dllexport)は、DLLで公開するための修飾。
intは、脱出関数なので返却値がint。
__cdeclは呼出規約。
hello_は関数名であり、何でもよいです。
(addr rest)の引数は、addrを一つにしてください。
引数はいくつかの形から選ぶことができるのですが、
ここではあんまり説明しません。
作成したhello_関数の内容は、だいたい次のような感じになります。
(defun hello_ (&rest rest) "Hello")
あと今更ですが__declspec(dllexport)ではなく
defファイルを用意する方法もあるらしいです。
詳しくは知りません。
以上でDLLファイルが作成できるはずです。
ここではaaa.dllという名前で作成したことにして話を進めます。
3. nptで実行
npt for Windowsを起動してください。
たぶんコマンドプロンプトのnptでも問題ないです。
あと、同じディレクトリにaaa.dllをコピーしてください。
まずは操作が面倒なのでnpt-systemパッケージをuseします。
* (use-package 'npt)
最近、npt-systemにnptというnicknameを付けました。
けっこう便利です。
DLLを読み込むには、dlfile関数を使用します。
dlfileの第一引数にopenを指定します。
* (dlfile 'open "aaa.dll") ;; ★注意 #<PAPER 0 ...>
dlfileのopenは、指定したDLLファイルを読み込みます。
DLLファイルと認識できたら、最初にlisp_dlfile_main関数を探して呼び出します。
もしlisp_dlfile_main関数が存在しなかった場合は例外が発生します。
またlisp_dlfile_main関数を実行した結果、0以外が返却された場合も例外です。
全てが成功した場合は、PAPERオブジェクトが返却されます。
この返却されたオブジェクトがないと何もできませんので、 何かの変数に代入してください。
* (setq x (dlfile 'open "aaa.dll")) #<PAPER 0 ...>
DLLから関数を呼び出すためには、まずは関数を探します。
次のように実行してください。
* (setq y (dlfile 'call x "hello_")) #<PAPER 0 ...>
DLL内にhello_という関数が存在しなかった場合は例外が発生します。
成功した場合は、PAPERオブジェクトが返却されます。
openの時と同様、何かの変数に格納してください。
注意してほしいのは、返却値は関数ではないということです。
呼出しを行う場合は、dlcall関数を使用します。
* (dlcall y) "Hello"
DLLで作成したコードが実行されたことが分かります。
DLLを開放する処理もあります。
dlfileにcloseを指定してください。
* (dlfile 'close x)
これでDLLは解放されます。
このときdlcallでyを呼び出すと例外が発生します。
dlfileとdlcallによって返却されたオブジェクトは、
そのプロセス限りの使い捨てだということを覚えておいてください。
返却値はPAPERオブジェクトなのでcoreファイルやfaslファイルで保存できます。
しかし保存されたものを使用しても正しく動作はしませんし、
おそらくはプロセスが壊れます。
3. 引数の形
後で仕様を変更するかもしれないので暫定ですが、引数の形を指定できます。
標準ではextend-restという型であり、
dlcallに渡された引数がすべてhello_の第一引数に指定されます。
例えば、
* (dlcall y 10 20 30)
として呼び出した場合は、DLL関数の
__declspec(dllexport) int __cdecl hello_(addr rest) { ... }
引数restに、(10 20 30)のコピーが渡されます。
本当はコピーではなく、内部のデータをそのまま渡したかったのですが、
lisp.hの関数がdynamic-extentのデータに対応してなかったので、
仕方なくコピーしました。
暫定と言っているのはこういう部分です。
変更した例を示します。
まずはDLL関数から。
__declspec(dllexport) int __cdecl arg2_(addr x, addr y) { if (lisp_stdout8_("Value1: ~S~%", x, NULL)) return 1; if (lisp_stdout8_("Value2: ~S~%", y, NULL)) return 1; lisp_set_result_control(Lisp_nil()); return 0; }
この関数を取得するときに、extend-var2引数を指定します。
* (setq x (dlfile 'open "aaa.dll")) * (setq y (dlfile 'call x "arg2_" 'extend-var2))
実行は次の通り。
* (dlcall y 10 20) Value1: 10 Value2: 20 NIL
extend-var2は、引数が2つでないとエラーが発生します。
型にどのような種類があるのかは、process_calltype.cに書かれていますが、
extend-restという名前も不格好であり後で変えるかもしれません。
npt for Windowsのコンパイル方法
以前の投稿でnpt-windowsのバイナリを配布しました。
nptのWindows版を公開します - nptclのブログ
ウィルスというか、トロイの木馬報告もされました。
npt64.exeのウィルス検出について - nptclのブログ
ここでは手動でnpt-windowsをコンパイルする方法について説明します。
作者はVisual Studio 2017を使って確認しています。
まずはソースを用意してください。
このリポジトリに、Windows用のソースも含まれています。
場所は下記の通り。
npt/develop/windows/.
コンパイルは、下記の値をdefineします。
LISP_WINDOWSLISP_TERMELISP_WINMAIN
FreeBSDとLinuxでコンパイルする場合は、LISP_TERMEがデフォルトで指定されます。
しかしWindowsの場合は、LISP_STDINがデフォルトです。
上記のようにLISP_WINDOWSとLISP_TERMEを両方指定することで、
Windowsアプリケーションを作成することができます。
このモードでコンパイルする場合は、Windows用のソースを追加で指定する必要があります。
ソースは下記の場所に存在します。
develop\windows上windows_*.cwindows_*.h
ビルド用のMakefileではincludeパスとソースパスを指定しているため
場所を意識する必要はありませんが、
手動で実行する場合は自分で何とかしなければいけません。
色々と方法はあると思いますが、
nptのソースファイル一式と、上記のWindows用ソースを
一か所にまとめるとコンパイルしやすいかと思います。
Windowsアプリケーションとしてコンパイルする場合は、
コンソール画面を表示しないようにする必要があります。
設定は次の2つにて行います。
LISP_WINMAINをdefineするLINK.EXEに/SUBSYSTEM:WINDOWSを指定する
コンパイルの例を示します。
まずはCL.EXEとLINK.EXEを利用できる状態にしてください。
カレントディレクトリに、nptのソースとWindowsのソースが存在しているものとします。
まずはコンパイルを行います。
> CL.EXE /C /DLISP_WINDOWS /DLISP_TERME /DLISP_WINMAIN *.c
コンパイルが成功すると、objファイルが生成されます。
次にリンクを行います。
> LINK.EXE /OUT:npt.exe *.obj Shell32.lib User32.lib Gdi32.lib /SUBSYSTEM:WINDOWS
ライブラリは、次の3ファイルを指定する必要があります。
Shell32.libUser32.libGdi32.lib
正常に実行された場合は、npt.exeが出力されます。
生成されたnpt.exeは通常のWindowsアプリケーションなので、
実行するとウィンドウが表示されます。
コンパイルのためのスクリプトも用意しています。
buildディレクトリ上をご確認ください。
- 構築スクリプト
windows_terme_debug.batwindows_terme_release.bat
- Makefile一式
Makefile.windows_terme_debugMakefile.windows_terme_release
- Visual Studio 2017用
vs2017_terme_debug64.batvs2017_terme_release64.bat
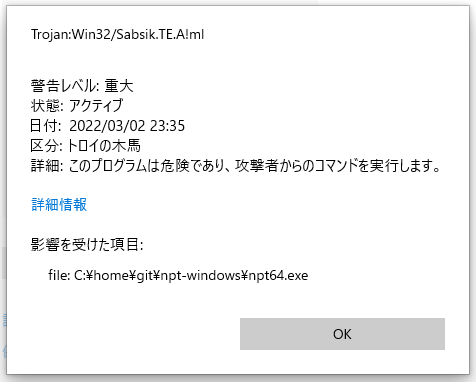
npt64.exeのウィルス検出について
Microsoft Defenderから脅威が検出されました。
でもトレンドマイクロのオンラインスキャンでは問題なし。
誤動作の可能性があるので報告します。
下記のファイルです。
64bit版実行ファイル
https://nptcl.github.io/npt-windows/npt64.exe
検出内容
Trojan:Win32/Sabsik.TE.A!ml
Trojan:Win32/Wacatac.B!ml
★2022/03/03にnpt64.exeを更新したらWacatac.B!mlに変わってました。
★いくらなんでもおかしいだろ
怪しいので、上にも書きましたがトレンドマイクロのオンラインスキャンでもチェックしました。 問題なく、脅威は検出されませんでしたとのこと。
npt32.exeとnpt64.exeのコンパイルは、
バッチファイルで構築した直後にmd5を取っており、
githubに送信する前にちゃんと改ざんされないか確認しています。
たぶん誤動作じゃないかなあと思うんですが、どうなんでしょうね。
再コンパイルした後でも検出されましたので放置しようと思います。
作者である私の環境を信頼する必要は全くありませんし、
むしろ疑ってくれた方がよいかと思いますが、
トレンドマイクロさんのスキャンで問題ないとの結果が出たのはうれしいです。
不安な人は自分でコンパイルしてください。
npt for Windowsのコンパイル方法を別で載せます。
npt for Windowsのコンパイル方法 - nptclのブログ
検出画面はこちら
問題なかった画面はこちら
